 HuggingFace
HuggingFace
Abstract
This work introduce Multiverse, a new generative modeling framework that enables natively parallel generation. Multiverse internalizes a MapReduce paradigm through three stages: (i) a Map stage for adaptive task splitting, (ii) a Process stage for parallel subtask execution, and (iii) a Reduce stage for lossless result merging.
Next, we build a real-world Multiverse reasoning model with a co-design of data, algorithm, and system, enabling rapid and seamless transfer from frontier AR-LLMs:
- Multiverse Curator: An automated LLM-assisted pipeline that converts sequential chains into Multiverse structures.
- Multiverse Attention: A new attention mechanism that separates parallelizable branches while supporting efficient training.
- Multiverse Engine: An efficient generation engine that dynamically switches between sequential and parallel generation.
After a 3-hour fine-tuning with 1K examples, Multiverse-32B is the only open-sourced non-AR model to match the performance of leading AR-LLMs of the same scale, scoring 54% and 46% on AIME24 & 25, respectively. Moreover, it exhibits superior scaling, outperforming AR-LLMs by 1.87% on average, which results in up to a 2x speedup.
Multiverse Evaluation
What we can achieve with Multiverse
Real-world Reasoning Capability
| Model / Metric | AIME24 | AIME25 | MATH500 | GPQA-Diamond | ||||
|---|---|---|---|---|---|---|---|---|
| pass@1 | # parallel | pass@1 | # parallel | pass@1 | # parallel | pass@1 | # parallel | |
| s1-32B | 35.4 | 1.00 | 25.8 | 1.00 | 88.6 | 1.00 | 48.0 | 1.00 |
| s1.1-32B | 52.9 | 1.00 | 41.7 | 1.00 | 93.4 | 1.00 | 62.6 | 1.00 |
| Qwen2.5-32B-Instruct | 15.8 | 1.00 | 10.4 | 1.00 | 80.4 | 1.00 | 47.0 | 1.00 |
| Autoregressive-32B | 54.6 | 1.00 | 45.0 | 1.00 | 92.8 | 1.00 | 61.6 | 1.00 |
| Multiverse-32B-zero | 52.1 | 1.04 | 44.2 | 1.05 | 92.4 | 1.12 | 63.6 | 1.17 |
| Multiverse-32B | 53.8 | 1.18 | 45.8 | 1.15 | 91.8 | 1.15 | 60.7 | 1.17 |
Multiverse-32B achieves significant improvements over the Qwen2.5 model by 24.5% after SFT on Multiverse-1K, while matching or exceeding the performance of AR-LLMs.
Efficient Scaling Capability
GPQA-Diamond Scaling
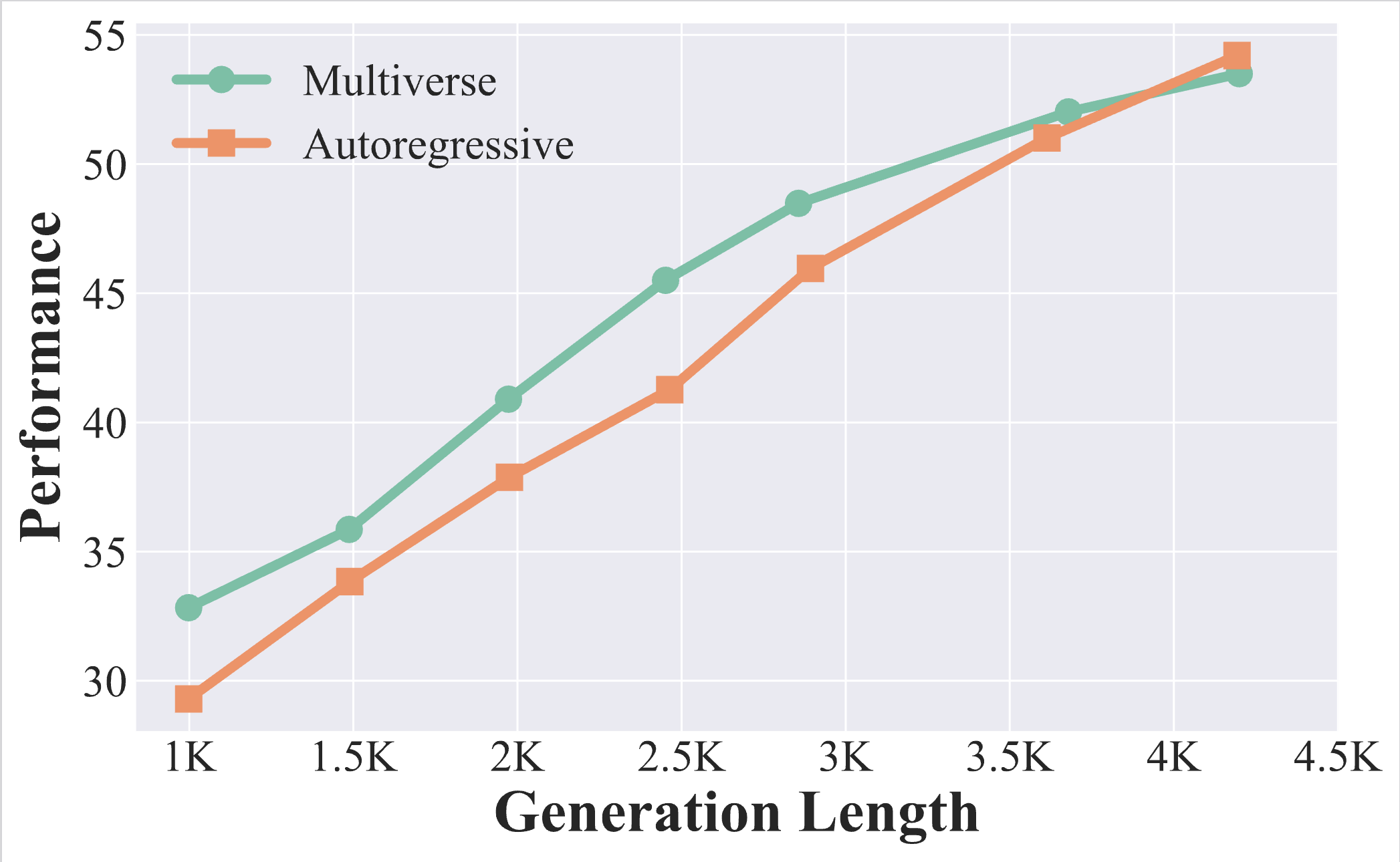
MATH500 Scaling
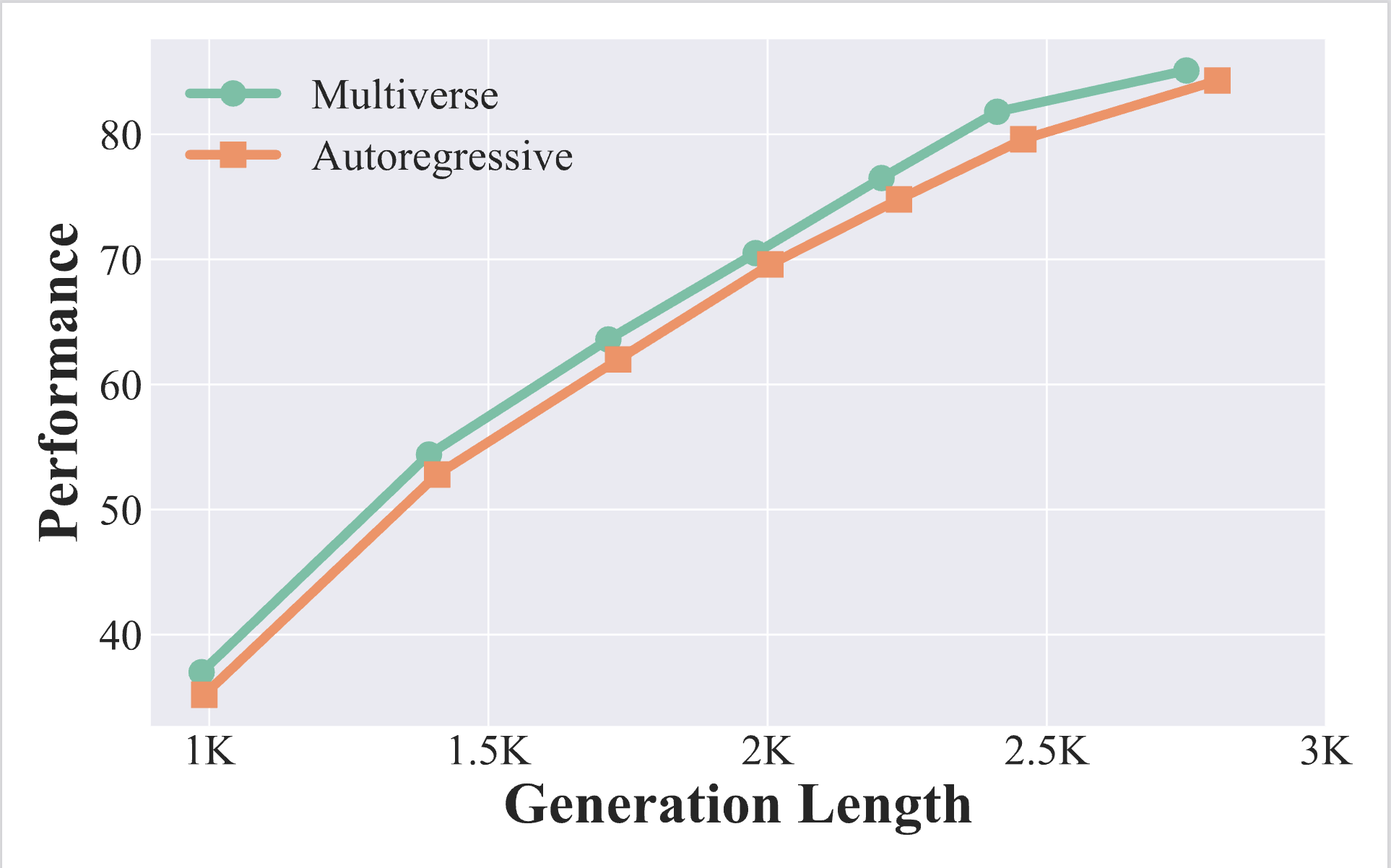
Multiverse-32B exhibits a superior tradeoff between performance and latency than AR-LLMs. It achieves this by generating more tokens within the same wall-clock time.
Practical Efficiency Analysis
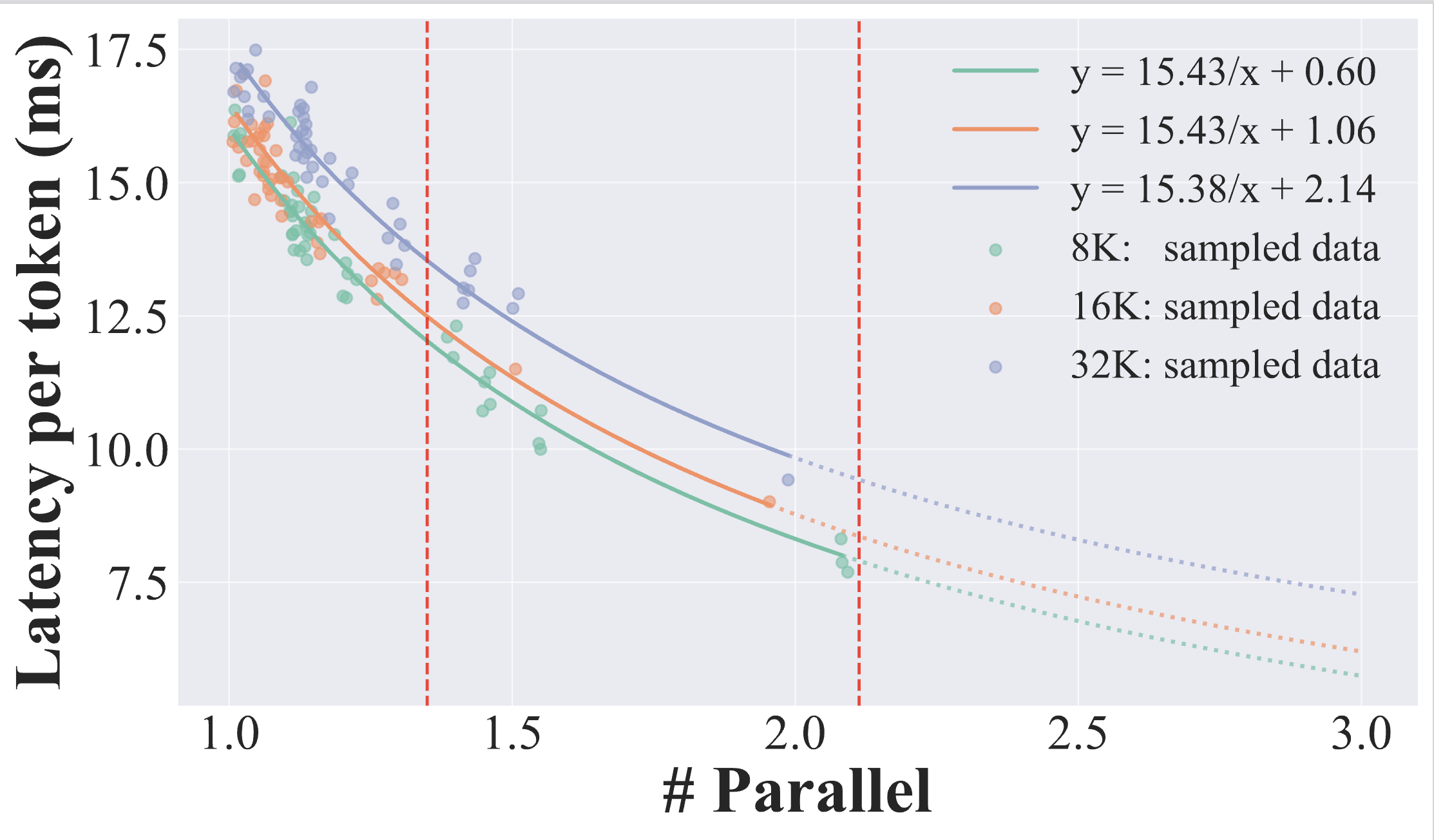
Speedup vs. Parallelism
Throughput vs. Parallelism
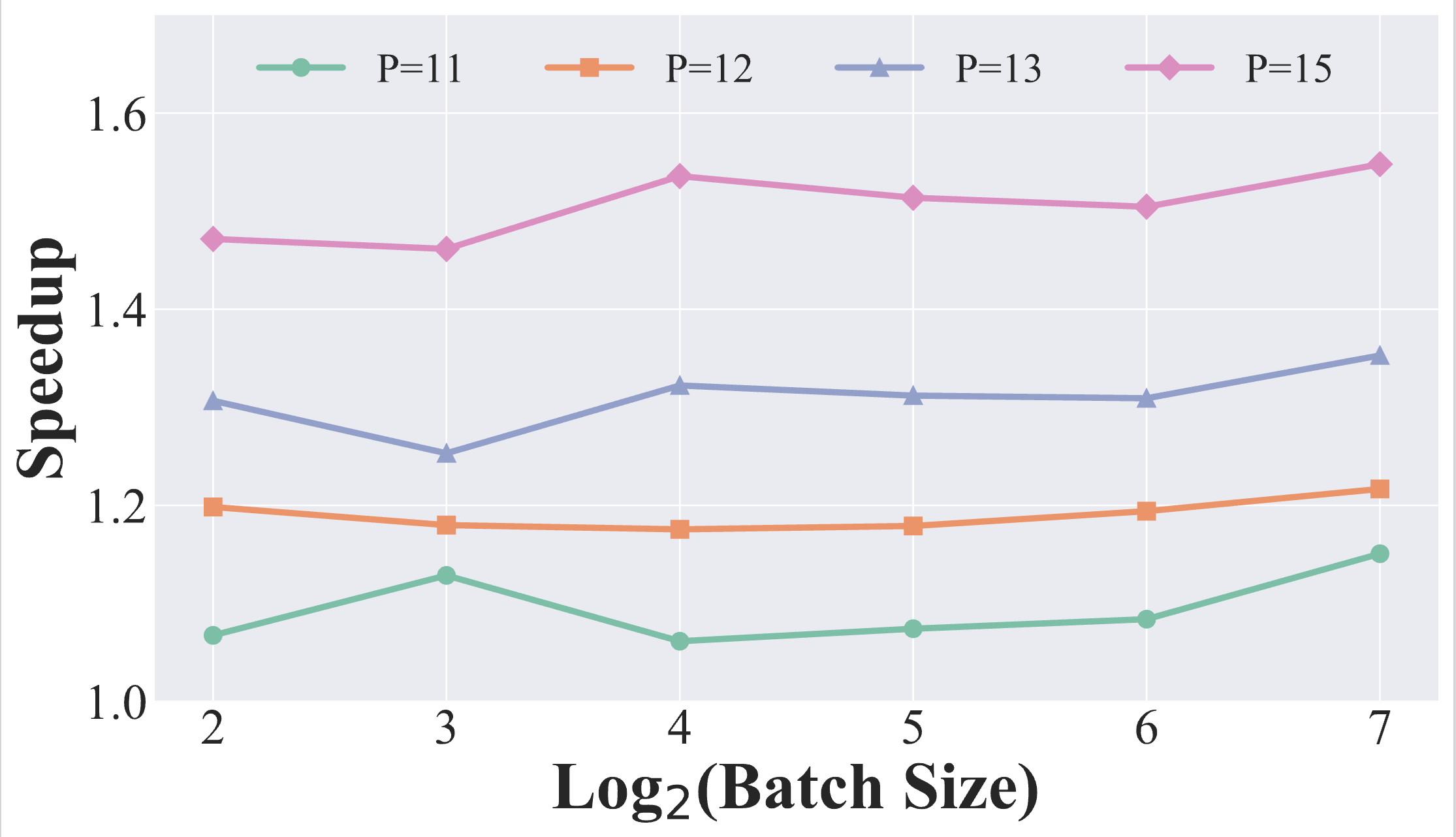
Multiverse-32B achieves up to 2x wall-clock speedup per generated token while maintaining effective scaling across variable batch sizes.
Multiverse Training
Explore the parallelism in Multiverse 1K
We train the Multiverse model using the curated Multiverse-1K corpus. Click one id to view the corresponding example.
How to Build a Multiverse Model
Understanding the co-design of data, algorithm, and system
Data: Multiverse Curator
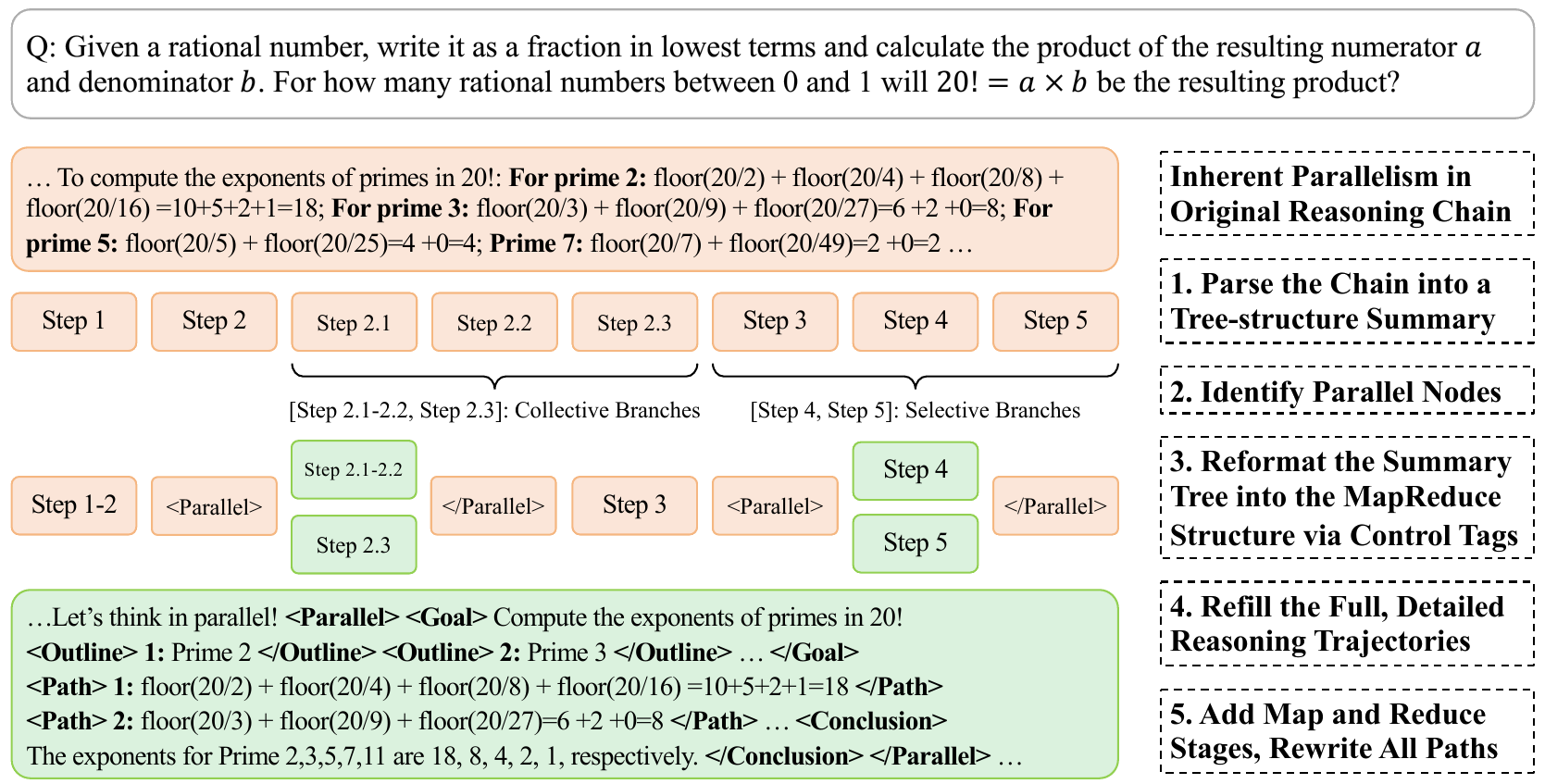
Figure (a): Multiverse Curator automatically generated Multiverse-1K using an LLM-assisted data curation pipeline.
To address this absence of MapReduce structures in existing
data, we develop Multiverse Curator, an automated LLM-assisted pipeline that transforms sequential chains into parallel structures via five steps: (i) parsing the sequential chain into a summary tree; (ii) identifying parallelizable nodes within the summary tree; (iii) reformatting the summary into a parallel generation structure; (iv) refilling original reasoning steps into this structure; and (v) adding Map & Reduce stages while rewriting the Process stage. Moreover, content and grammar checks are performed to flag low-quality data for regeneration, avoiding costly manual filtration and annotation. In practice, this process results in Multiverse-1K, a dataset of 1,000 high-quality structured training samples for advancing LLM reasoning.
Algorithm: Multiverse Attention
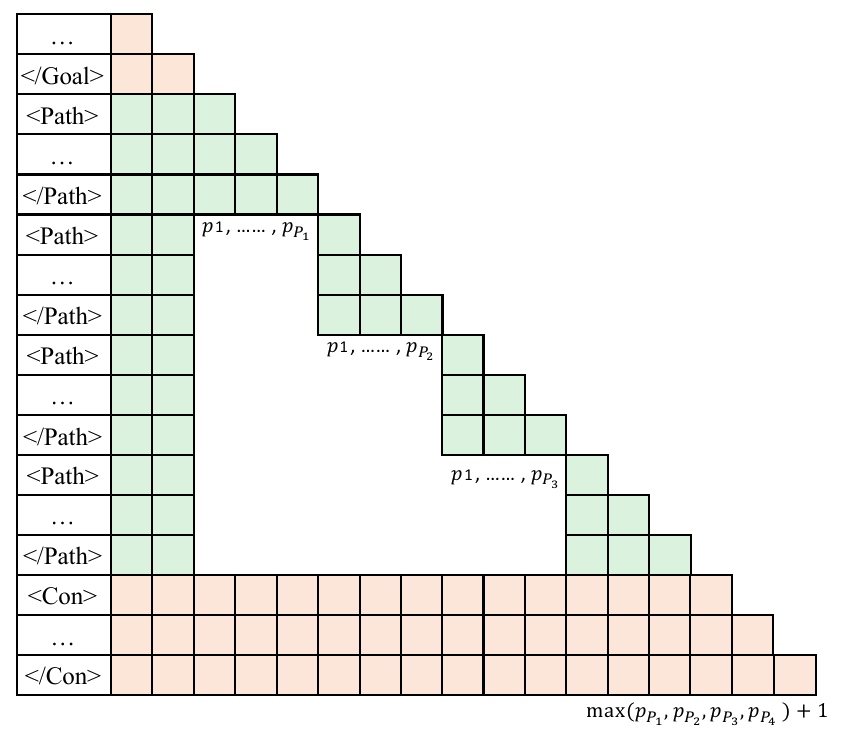
Figure (b): Multiverse Attention.
To enable conceptually parallel generation, we design Multiverse Attention by modifying both the attention masks and position indices. In Multiverse Attention, each path within the same Process block starts from an identical position and executes independently without accessing others. During the Reduce stage, all paths converge to the same position, which is set to the maximum position reached by any path to avoid negative relative distance, regardless of their variable lengths. Building on its similarity to causal attention, Multiverse Attention enables (i) Hardware Efficiency: it can preserve training parallelism, and (ii) Data Efficiency: it can be rapidly adapted via fine-tuning on a few samples. For more details about this attention variant, please refer to our past work: APE: Faster and Longer Context-Augmented Generation via Adaptive Parallel Encoding.
System: Multiverse Engine
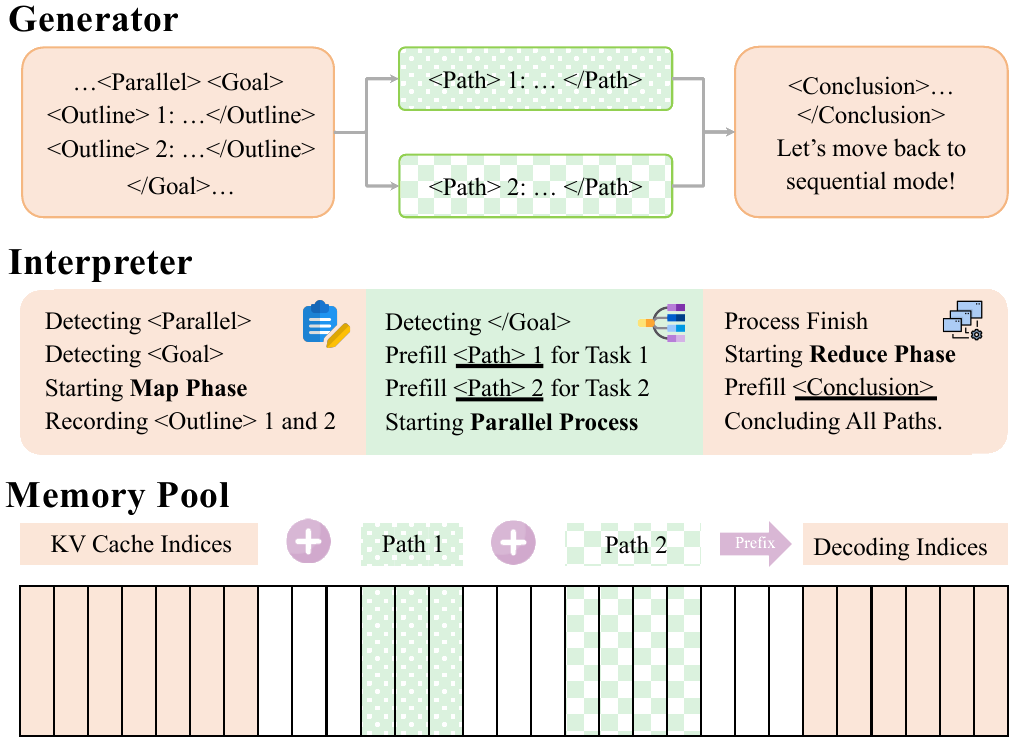
Figure (c): Multiverse Engine.
To enable truly parallel generation in practical deployments, we implement Multiverse Engine, an extension of existing inference engines designed for AR models. Specifically, we start from SGLang due to its support for continuous batching and radix attention. These features allow dynamic batch scheduling and flexible KV-cache reuse for Multiverse, two scenarios that frequently occur in the Map and Reduce stages. In the Map stage, subtasks are delineated using special tags and dispatched to separate execution paths in parallel, all sharing the prefix KV cache from the current context to maximize reuse efficiency. In the Reduce stage, the Key-Value (KV) indices from all paths are seamlessly concatenated into a single sequence, avoiding both physical memory copying and redundant padding computations. Our implementation of Multiverse Engine is open-sourced on GitHub.
Acknowledgments
We thank Zhuoming Chen, Haizhong Zheng, Ranajoy Sadhukhan, Yang Zhou, Songlin Yang, Liliang Ren, Wentao Guo, Ruijie Zhu, Yu Zhang, and Yixin Dong for their constructive feedback on this work, along with the authors of s1, SGLang, and LightEval for their useful codebase. We are also grateful to BitDeer AI Research for providing GPU resources and to Google for supplying Gemini API credits. This research was supported in part by a DGX B200 gift from NVIDIA, a Google Research Award, an Amazon Research Award, Intel, Li Auto, Moffett AI, and the CMU CyLab Seed Fund.